 2018, Vol. 38
2018, Vol. 38



氚(3H或T)是氢(1H)元素的一种具有放射性的同位素,半衰期为(12.33±0.03) a(Lucas et al., 2000),常被作为降水输入的示踪信号对地下水进行研究(程中双, 2015; 许乃政, 2015; 靳书贺等, 2016; Gleeson et al., 2016; Cauquoin et al.2017),如Gleeson等(2016)利用氚对全球现代地下水含量及分布进行了研究.在地表水和地下水领域,常利用水中氚浓度进行定量研究.如王绍令等(1990)利用各类水(冰)中氚含量研究了青藏高原多年冻土区地下水动态变化、水力联系;崔亚莉等(2015)利用氚浓度数据建立数学物理模型,计算了诺木洪地区冲洪积扇不同位置地下水的更新速率;Birkel等(2016)利用氚作为示踪剂研究了降雨和径流过程等.这些利用水中氚浓度开展的定量研究往往需要降雨中的氚浓度值作为背景值(王瑞久, 1984; 连炎清, 1990; 马致远等, 1997; 陈宗宇等, 2004; 马致远, 2004; 张应华等, 2006).然而,大气降水氚浓度历史观测数据(以下简称实测数据)稀少且空间分布不均,仅有少部分地区能直接使用由国际原子能机构(International Atomic Energy Agency, IAEA)和世界气象组织(World Meteorological Organization, WMO)在全球范围建立的有限站点的观测数据,而大多数地区只能借助于实验手段获取数据,或基于IAEA及WMO公布的站点数据采用数学方法进行恢复(连炎清, 1990).实测数据的缺失成为广大水文工作者利用氚进行研究的极大障碍.
大气降水氚浓度恢复模型研究中,前人提出的数学分析方法主要有吴秉钧法(吴秉钧, 1986)、插值法(王凤生, 1998; 巴琦等, 2010)、双曲线参考法(连炎清, 1990)、不同影响因素的一元线性相关法(马致远等, 1997)、人工神经网络法(龙文华, 2008)、因子分析法(Doney et al., 1992; Zhang et al., 2011; 章艳红等, 2011)等.因子分析法恢复氚浓度相比于上述其他方法而言,在实际应用上较为简单,而且从恢复结果上来看,其具有更长时间和更大空间的适用性.Doney等(1992)于1992年首次将因子分析法应用于大气降水年均氚浓度分析,并由此建立了1960—1986年间的全球大气降水氚浓度模型(GMTP).章艳红等(2011)基于GMTP模型建立了改进的全球大气降水氚浓度模型(MGMTP),可以恢复全球1960—2005年大气降水年平均氚浓度.对比Doney等及章艳红等的模型发现,其区别主要在于因子获取过程中,Doney等是先对实测数据进行衰变矫正后,再应用协方差矩阵求解因子得分与因子载荷;而章艳红等是直接对实测数据进行标准化相关阵处理.GMTP模型涉及的时间序列较短,通过衰变矫正可以减小数据间的量级差异以便直接采用协方差矩阵进行无损原始变量离散程度差异处理(金在温等, 2015);而MGMTP模型中数据恢复年份序列较长,实测数据取值范围大,进行衰变矫正有可能导致低氚浓度值数据的数值过小且后续使用数据时面临需对衰变数据进行恢复的麻烦,因此,MGMTP模型直接对实测数据进行了标准化相关阵处理.以上两种模型均根据实测数据情况选择了合适的方法,其中,MGMTP模型更适合较长时间序列数据恢复,但该模型现已面临适用年限有限的问题,即数据只恢复到2005年;另外,该模型对1990年后数据的恢复不理想,负值出现频率较高.
本文基于MGMTP模型的理论和方法,对该模型出现的拟合结果出现异常负值问题及其解决方法进行进一步明确与改进,并将该模型扩展到2014年.同时,考虑到IAEA和WMO提供的站点有一部分建成时间较晚,有一部分仅有些不连续性的实测数据,导致这些站点的实测数据在时间序列上不连续或仅有短期数据,与GMTP模型和MGMTP模型不同,本次研究拟针对这一问题进行数据预处理.
2 模型建立(Model establishment)前人对实测数据的观察和研究表明,全球各测站中大气降水的氚浓度年均变化在各自半球内具有相似的曲线形态(Doney et al., 1992; Koster et al., 1989; Michel, 1992),这就为本研究利用因子分析法导出参考曲线进而对全球各地区降水年平均氚浓度变化进行归纳、模拟、恢复提供了依据.因子分析法的基本思想是根据相关性把原始变量分组,使同组内变量之间的相关性较高(即它们的共性成分较多)而不同组变量之间的相关性较低(即它们的共性成分较少).由此得到的共性成分称为公共因子,而与公共因子无关的则称为特殊因子(李永江等, 2016).在获得公共因子得分后,进而应用公共因子建模.
MGMTP模型在获取公共因子得分时,对分组内的数据缺乏分析整理,导致特殊因子占比较大,所求公共因子得分不能代表大部分数据特征,导致模型恢复的氚浓度时间序列数据在后期出现负值.了解到负值数据出现的本质原因,本文在数据处理时采取了特定预处理方法,取得了较好效果.
2.1 公共因子得分求解本文全部的数据分析资料均来自IAEA和WMO官网提供的氚浓度值监测数据(IAEA&WMO, 2016),数据按站点的监测时间序列(1960—2014年)列表给出,共计612个站点.数据处理是基于SPSS(Statistical Product and Service Solutions),即“统计产品与服务解决方案”这一软件为平台实现的.本文的数据分析方法与MGMTP模型在公共因子获取方法上(章艳红等, 2011; Zhang et al., 2011)稍有不同.
考虑到监测站点分布的空间情况,本文只对站点分布较为集中的南纬50°(记为-50°,本文南纬纬度均用负值表示)至北纬70°之间的区域进行恢复.首先,本文对数据进行特殊预处理:①删除个别极端值,此外,考虑到不足3组监测数据的站点不仅不能反映该地区的氚浓度值变化趋势,还会给分组内的其它数据带来干扰,本文对其进行了删除以减少特殊因子对模型的影响;②由于IAEA和WMO对某些地区的站点进行了年份选择性监测,部分站点在实测数据接近背景值后便停止了数据监测,进而导致这些站点缺乏近年来的监测数据.变量分组时,由于这部分数据无规律地出现或缺失,组内均值出现异常波动.基于上述原因,考虑到现今大气中氚的输入源主要为宇宙输入(章艳红等,2011),2005年之前的数据稳定、变化小于1TU但之后无监测记录的站点,按照同分组内其他站点监测数据变化规律合理插值至2014年.数据经预处理后,开始数据分析:将站点数据按每10°纬度带进行分组并标准化原始数据,使其每一分带内的数据均值为0、方差为1;建立相关矩阵、求其特征值和标准化单位特征向量.通过对特征值累计贡献率,即累计方差贡献率的计算(图 1),发现前两个特征值累计贡献率已达94.31%,说明前两个因子包含了全部数据的绝大部分信息,所以本研究用这两个特征值建立初始因子载荷矩阵.考虑到因子载荷阵的不唯一性及为了寻找更简单和更容易解释的因子,本研究又对初始因子载荷阵施行方差最大正交旋转,使得各个因子在各纬度分带上的载荷取值尽可能的两极分化(靠近0或1),满足一个纬度分带只在一个因子上有较大载荷,以便因子可以由纬度分带进行差异性解释(图 2a),即因子的大小具有纬度效应(章艳红等, 2011).最后按照因子得分函数估计最终公共因子得分(表 1).
 |
| 图 1 公共因子个数和方差信息损失量关系曲线 Fig. 1 Plot of the numbers of factors vs. uncounted variances |
 |
| 图 2 1960—2014年旋转因子载荷(最大方差旋转法)(a.横坐标负值表示南纬,正值表示北纬)及因子得分曲线(b) Fig. 2 Factor loadings rotated by maximum variance rotation method (a) and factor scores calculated from the zonally averaged precipitation tritium data(b) |
| 表 1 预测降水中氚浓度(单位:TU)的标准化公因子得分 Table 1 Normalized factors score for predicting tritium in precipitation |
在得到随年份变化的公共因子得分后,再利用最小二乘法对实测数据进行多元线性拟合,由此得到模型参数的过程称为直接求参法,即:

|
(1) |
式中,CP(t)为随年份变化的氚浓度,f1、f2分别为公因子得分CP(t, 1)、CP(t, 2)的回归系数,b值为回归拟合数据均值,ε为误差项,经过多元线性拟合得到的方程(1)(何晓群, 2010; 汪东华, 2010)就是所说的全球大气降水中年平均氚浓度恢复模型.
运用直接求参法求解的站点需要具有5年以上核爆中期(20世纪60年代)的监测数据.因为通过公因子得分曲线(图 2b)可以看出,这两条曲线在核爆之后虽然有数值上的差异(Weiss et al., 1980),但形状上却具有相似性,若没有核爆中期的数据对模型进行总体控制,将会导致求解方程(1)出现困难或假解(Doney et al., 1992).
2.2.2 间接求参法通过直接求参法求得的参数只能用于本站点的数据恢复,由于满足直接求参法求解的站点数有限(部分恢复结果见表 2),对于广大没有该类站点的地区,应用间接求参法求解参数是模型的关键.
| 表 2 部分直接求参法恢复的站点模型参数及其代表性检测 Table 2 Part of the station model parameters calculated by thedirect solution method and their representative testing |
间接求参法是将符合直接求参法求解要求的全部站点作为基站点,利用临近站点模型参数进行插值以估算全球范围内任意一点氚浓度的方法.该方法不要求氚浓度恢复地区具有长时间监测序列(精度允许的情况下甚至不要求有监测数据),但仍可以计算全球任意位置的年均氚浓度.
2.3 模型恢复实例与检测 2.3.1 直接求参法为了验证直接求参法模型拟合效果,本文对恢复结果进行了回归模型代表性检测,包括对修正拟合优度系数(R2)、显著度(F)检测、估计标准误差(SEE)3个常用监测指标的计算.任取南、北半球具有代表性的监测站点,线性拟合模型如下.
新西兰凯托克(Kaitoke,41.10°S,175.17°E),CP(t)=8.106+2.634×CP(t, 1)+9.210×CP(t, 2),该站点的R2为0.942,SEE为2.434,且通过F检测,显著度明显.
中国香港(HongKong,22.32°N,144.17°E),CP(t)=39.610+104.367×CP(t, 1)+32.428×CP(t, 2),该站点的R2为0.923,SEE为8.421,且通过F检测,显著度明显.
加拿大渥太华(Ottawa,45.32°N,75.67°W),CP(t)=181.321+437.445×CP(t, 1)+154.021×CP(t, 2),该站点的R2为0.989,SEE为50.276,且通过F检测,显著度明显.
3组数据与实测数据的对比见图 3a~c,其它直接求参法求得的部分站点模型恢复参数及其代表性检测数据见表 2.
 |
| 图 3 模型恢复氚浓度与实测值对比图(a.凯托克, b.香港, c.渥太华站-直接求参法, d.凯塔亚站-间接求参法) Fig. 3 Comparisons of observed and predicted annual mean tritium concentrations in precipitation in Kaitoke(a), HongKong(b), Ottawa stations with the direct calibrated parameters(c) and Kaitaia station with the interpolated parameters(d) |
同MGMTP模型一致,本文同样对间接求参法的应用进行举例验证.为了更好的体现模型恢复效果,选用实测数据较多的凯塔亚站(Kaitaia,35.07°S,137.28°E)作为待对比的站点.首先,选取与Kaitaia临近的且可通过直接求参法求得模型参数的两个站点,即Kaitoke(41.10°S,175.17°E)及Rarotonga-Cook Island(35.27°N,75.35°W站点恢复模型:CP(t)=3.766+1.751×CP(t, 1)+3.193×CP(t, 2))作为间接求参的参考点.然后,利用纬度关系对Kaitaia站点的待求参数进行线性插值,得到其模型为:CP(t)=6.791+2.366×CP(t, 1)+7.387×CP(t, 2),该模型计算结果与实测数据的对比见图 3d.
3 模型改进与探索(Model improvement and exploration)本文提出了2个特殊数据预处理方法,一是删除不足3组监测数据的站点,二是对缺少近期监测数据站点的数据进行合理化延长.为了考察这些数据预处理方法对模型恢复结果的影响,本文做了相关模型之间的对比,结果显示,该处理方法在达到应用精度要求的情况下,极大地降低了负值站点出现的频率,使一次性得到模型参数的站点数得到了较大提升(表 2).
在经过如前所述的数据预处理后,部分站点在20世纪90年代后的恢复数据还是会出现负值.除去因子分析法本身带有的系统误差外,出现负值的主要原因是站点后期,尤其是1990年后监测数据不足.在应用最小二乘法多元线性拟合时,模型数据尽可能地拟合现有的监测数据,而对没有监测数据控制的模型后期恢复数据,会偶现不符合实际情况的负值.出现负值的解决方法在MGMTP模型中有介绍(章艳红等, 2011):包括背景值替代、同纬度分带内插值及分段处理法等.本文就其提出的第3种方法——分段处理法,做进一步说明与改进.
在有1990年后(至少是1980年后)监测数据的情况下,可直接利用MGMTP模型提及的分段处理法来对负值进行消除.以美国Albuquerque站点为例(图 4),1960—1989年分段及1990—2014年分段的模型参数分别为:
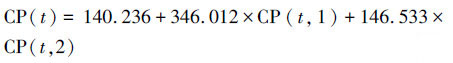
|
(2) |
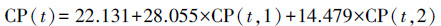
|
(3) |
 |
| 图 4 1990年代后有实测数据的负值修复情况 Fig. 4 Restoration with monitoring data after the 1990s |
而对于那些缺少1990年后数据但之前实测数据量较多的站点,本文建议先利用临近站点对该点进行模型参数线性插值,然后将1990年后的插值数据加入实测数据序列,再利用直接求参法求解.这样做的目的是尽可能的利用实测数据,使叠加误差降到最低(直接求参误差相对较小,间接求参误差相对较大).
为了说明这种改进方法去除负值的效果,本文以美国的St.Louis(38.75°N,90.38°W)站点为例进行说明.
选用与St.Louis站点较近的加拿大的Ottawa(45.32°N,75.67°W)及美国的Hatteras(35.27°N,75.35°W; 站点恢复模型:CP(t)=53.538+127.305×CP(t, 1)+43.638×CP(t, 2))两站点对其进行纬度线性插值,得到初步的间接求参法模型:
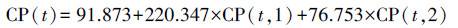
|
(4) |
用间接求参法模型计算出的1990年后氚浓度数据补足缺失的实测数据,然后再进行一次直接求参法拟合,拟合模型为:
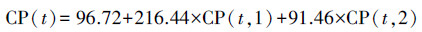
|
(5) |
通过图 5可以看出,该修正方法对于1990年代后无实测数据的站点给出了更为可靠的模型,恢复出更合理的氚浓度值.
 |
| 图 5 1990年代后无实测数据的负值修复情况 Fig. 5 Restoration without monitoring data after the 1990s |
对于少量拟合效果不佳的站点,可能与特殊的地形条件、水文条件、气象条件或局部地区人为影响等因素有关.此外,由于IAEA及WMO提供的数据相对全球尺度来说还是较为稀少,本文所做的是将可获取的实测资料最大化与最合理地整合利用到全球范围.站在全球尺度上来说,因子分析法对氚浓度值进行的模拟恢复已达到了应用的效果与精度.
该模型恢复精度受限于数据量,如果后期有其他来源的数据,可以将这些数据拟合到模型中,重新求取参数,并将其作为全球氚浓度的基站点以缩短插值距离,提高插值精度.如果有大量精准数据,就可以将这些数据导入该模型进行因子重算,进而推导出能与实测数据更为匹配的因子得分数据,以提高模型的精度及适应性.
4 结论(Conclusions)基于MGMTP模型的理论和方法,根据因子分析法分析数据的原理及监测数据的实际情况,进行了合理的数据预处理,重建了全球大气降水氚浓度模型.结果表明,本文提出的新模型不仅克服了MGMTP模型的氚浓度“异常负值”问题,而且能恢复全球1960—2014年间大气降水年平均氚浓度.同时,该模型具有简单易用、时间序列长、全球性适用等优点,对缺少大气降水氚浓度实测数据的地区具有重要参考价值.
巴琦, 徐永福. 2010. 氚输入函数的构造与北太平洋氚分布的模拟[J]. 中国科学:地球科学, 2010, 40(1): 115–126.
|
Birkel C, Soulsby C. 2016. Advancing tracer-aided rainfall-runoff modelling:a review of progress, problems and unrealised potential[J]. Hydrological Processes, 29(25): 5227–5240.
|
Cauquoin A, Jean-Baptiste P, Risi C, et al. 2017. Modeling the global bomb-tritium transient signal with the AGCM LMDZ-iso:a method to evaluate aspects of the hydrological cycle[J]. Journal of Geophysical Research, 121(21): 12612–12629.
|
陈宗宇, 聂振龙, 张荷生, 等. 2004. 从黑河流域地下水年龄论其资源属性[J]. 地质学报, 2004, 78(4): 560–567.
|
程中双. 2015. 强烈开采含水层的水化学和同位素响应及其水文地质指示[D]. 北京: 中国地质科学院
|
崔亚莉, 刘峰, 郝奇琛, 等. 2015. 诺木洪冲洪积扇地下水氢氧同位素特征及更新能力研究[J]. 水文地质工程地质, 2015, 42(6): 1–7.
|
Doney S C, Glover D M, Jenkins W J. 1992. A model function of the global bomb tritium distribution in precipitation, 1960-1986[J]. Journal of Geophysical Research Oceans, 97(C4): 5481–5492.
DOI:10.1029/92JC00015
|
Gleeson T, Befus K M, Jasechko S, et al. 2016. The global volume and distribution of modern groundwater[J]. Nature Geoscience, 9(2): 161–167.
DOI:10.1038/ngeo2590
|
何晓群. 2010. 应用多元统计分析[M]. 北京: 中国统计出版社: 253–316.
|
IAEA, WMO. 2016. GNIP Database: Global network of tritium in precipitation[OL]. https://websso.iaea.org.
|
靳书贺, 姜纪沂, 迟宝明, 等. 2016. 基于环境同位素与水化学的霍城县平原区地下水循环模式[J]. 水文地质工程地质, 2016, 43(4): 43–51.
|
金在温, 查尔斯·M·米勒. 2015. 因子分析: 统计方法与应用问题[M]. 叶华译. 上海: 格致出版社+上海人民出版社
|
Koster R D, Broecker W S, Jouzel J, et al. 1989. The global geochemistry of bomb-produced tritium:General circulation model compared to available observations and traditional interpretations[J]. Journal of Geophysical Research, 94(D15): 18305–18326.
DOI:10.1029/JD094iD15p18305
|
李永江, 刘春雨. 2016. 多元分析原理及应用[M]. 北京: 经济科学出版社: 78–107.
|
连炎清. 1990. 大气降水氚含量恢复的多元统计学方法:以临汾地区降水氚值恢复为例[J]. 中国岩溶, 1990, 9(2): 157–166.
|
龙文华, 陈鸿汉, 段青梅, 等. 2008. 人工神经网络方法在大气降水氚浓度恢复中的应用[J]. 地质与资源, 2008, 17(3): 208–212.
|
Lucas L L, Unterweger M P. 2000. Comprehensive review and critical evaluation of the half-life of tritium[J]. Journal of Research of the National Institute of Standards & Technology, 105(4): 541–549.
|
马致远. 2004. 环境同位素方法在平凉市岩溶地下水研究中的应用[J]. 地质论评, 2004, 50(4): 433–439.
|
马致远, 高文义. 1997. 用天然氚确定隐伏岩溶水滞留时间及含水层参数[J]. 煤田地质与勘探, 1997, 25(4): 34–38.
|
Michel R L. 1992. Residence times in river basins as determined by analysis of long-term tritium records[J]. Journal of Hydrology, 130(1/4): 367–378.
|
汪东华. 2010. 多元统计分析与SPSS应用[M]. 上海: 华东理工大学出版社: 93–226.
|
王凤生. 1998. 吉林省大气降水氚浓度恢复的区域模型探讨[J]. 吉林地质, 1998, 17(3): 75–81.
|
王瑞久. 1984. 山西娘子关泉的地下水储量估算[J]. 水文地质工程地质, 1984(6): 38–42.
|
王绍令, 李作福, 刘景寿, 等. 1990. 青藏高原东部地表水、地下水的氚同位素研究[J]. 环境科学, 1990, 11(1): 24–27, 23.
|
Weiss W, Roether W. 1980. The rates of tritium input to the world oceans[J]. Earth & Planetary Science Letters, 49(2): 435–446.
|
吴秉钧. 1986. 我国大气降水中氚的数值推算[J]. 水文地质工程地质, (4):42-45, 1986(4): 42–45, 53.
|
许乃政, 刘红樱, 魏峰, 等. 2015. 江苏洋口港地区地下水的环境同位素组成及其形成演化研究[J]. 环境科学学报, 2015, 35(12): 3862–3871.
|
章艳红, 叶淑君, 吴吉春. 2011. 全球大气降水中年平均氚浓度的恢复模型[J]. 地质论评, 2011, 57(3): 409–418.
|
Zhang Y, Ye S, Wu J. 2011. A modified global model for predicting the tritium distribution in precipitation, 1960-2005[J]. Hydrol Process, 25(15): 2379–2392.
DOI:10.1002/hyp.v25.15
|
张应华, 仵彦卿, 温小虎, 等. 2006. 环境同位素在水循环研究中的应用[J]. 水科学进展, 2006, 17(5): 738–747.
|